
Posted December 7, 2017
December 2017 Performance Working Group Progress Report
Scalability and performance are key features for Mesos. Some users of Mesos already run production clusters that consist of more than 35,000+ agents and 100,000+ active tasks. However, there remains a lot of room for improvement across a variety of areas of the system.
The performance working group was created in order to focus on some of these areas. The group’s charter is to improve scalability / throughput / latency across the system, and in order to measure our improvements and prevent performance regressions we will write benchmarks and automate them.
In the past few months, we’ve focused on making improvements to the following areas:
- Master failover time-to-completion: Achieved a 450-600% improvement in throughput, which reduces the time-to-completion by 80-85%.
- Libprocess message passing throughput: These improvements will be covered in a separate blog post.
Before we dive into the master failover improvements, I would like to recognize and thank the following contributors:
- Dmitry Zhuk: for writing a lot of patches for improving the master failover performance.
- Michael Park: for reviewing and shipping many of Dmitry’s more challenging patches.
- Yan Xu: for writing the master failover benchmark that was the basis for measuring the improvements.
Master Failover Time-To-Completion
Our first area of focus was to improve the time it takes for a master failover to complete, where completion is defined as all of the agents successfully reregistering. Mesos is architected to use a centralized master with standby masters that participate in a quorum for high availability. For scalability reasons, the leading master stores the state of the cluster in-memory. During a master failover, the leading master needs to therefore re-build the in-memory state from all of the agents that reregister. During this time, the master is available to process other requests, but will be exposing only partial state to API consumers.
The rebuilding of the master’s in-memory state can be expensive for larger clusters, and so the focus of this effort was to improve the efficiency of this. Improvements were made via several areas, and only the highest-impact changes are listed below:
Protobuf 3.5.0 Move Support
We upgraded to protobuf 3.5.0 in order to gain move support. When we profiled the master, we found that it spent a lot of time copying protobuf messages during agent re-registration. This support allowed us to eliminate copies of protobuf messages while retaining value semantics.
Move Support and Copy Elimination in Libprocess dispatch / defer / install
Libprocess provides several primitives for message passing:
dispatch: Provides the ability to post a messages to a localProcessdefer: Provides a deferreddispatch. i.e. a function object that when invoked will issue adispatch.install: Installs a handler for receiving a protobuf message.
These primitives did not have move support, as they were originally added prior to the addition of C++11 support to the code-base. In order to eliminate copies, we enhanced these primitives to support moving arguments in and out.
This required introducing a new C++ utility, because defer takes on the same API as std::bind (e.g., placeholders). Specifically, the function object returned by std::bind does not move the bound arguments into the stored callable. In order to enable this, defer now uses a utility we introduced called lambda::partial rather than std::bind. lambda::partial performs partial function application similar to std::bind except the returned function object moves the bound arguments into the stored callable if the invocation is performed on an r-value function object.
Copy Elimination in the Master
With these previous enhancements in place, we were able to eliminate many of the expensive copies of protobuf messages performed by the master.
Benchmark and Results
We wrote a synthetic benchmark to simulate a master failover. This benchmark prepares all the messages that would be sent to the master by the agents that need to reregister:
- The benchmark uses synthetic agents in that they are just an actor that knows how to reregister with the master.
- Each “agent” will send a configurable number of active and completed tasks belonging to a configurable number of active and completed frameworks.
- Each task has 10 small labels to introduce metadata overhead.
The benchmark has a few caveats:
- It does not use executors (this would show improved results over what is shown below, but for simplicity the benchmark omits them)
- It uses local message passing, whereas a real cluster would be passing messages over HTTP.
- It uses a quorum size of 1, so writes to the master’s registry occur only on single local log replica.
- The synthetic agents do not retry their re-registration, whereas typically agents will retry with a backoff.
This was tested on a 2015 Macbook Pro with 2.8 GHz Intel Core i7 processor. Mesos was configured using: Apple LLVM version 9.0.0 (clang-900.0.38), with -O2 enabled in 1.5.0.
The first results represent a cluster with 10 active tasks per agent across 5 frameworks, with no completed tasks. The results from 1,000 - 40,000 agents with 10,000 - 400,000 active tasks:
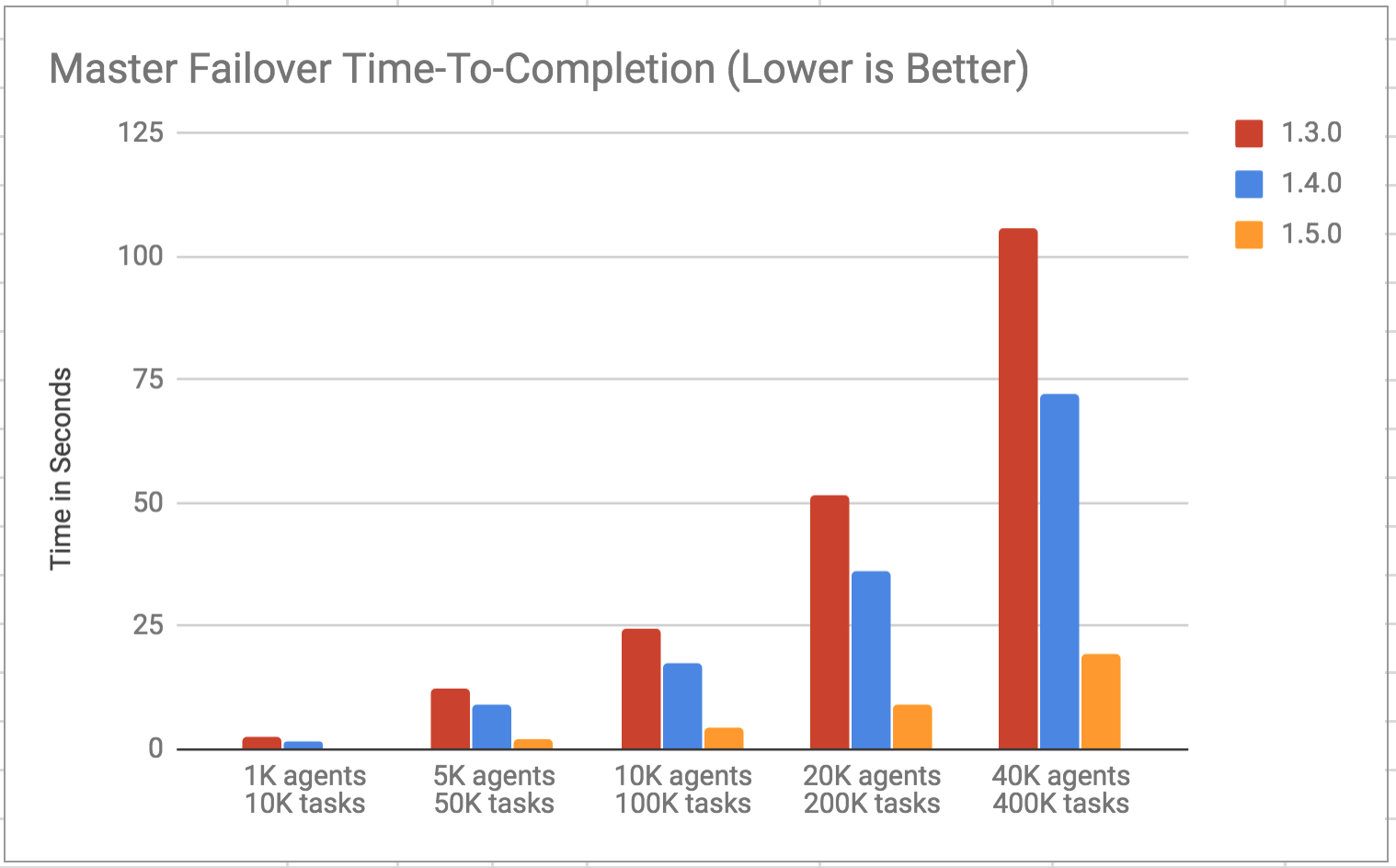
There was a reduction in the time-to-completion of ~80% due to a 450-500% improvement in throughput across 1.3.0 to 1.5.0.
The second results add task history: each agent also now contains 100 completed tasks across 5 completed frameworks. The results from 1,000 - 40,000 agents with 10,000 - 400,000 active tasks and 100,000 - 4,000,000 completed tasks are shown below:
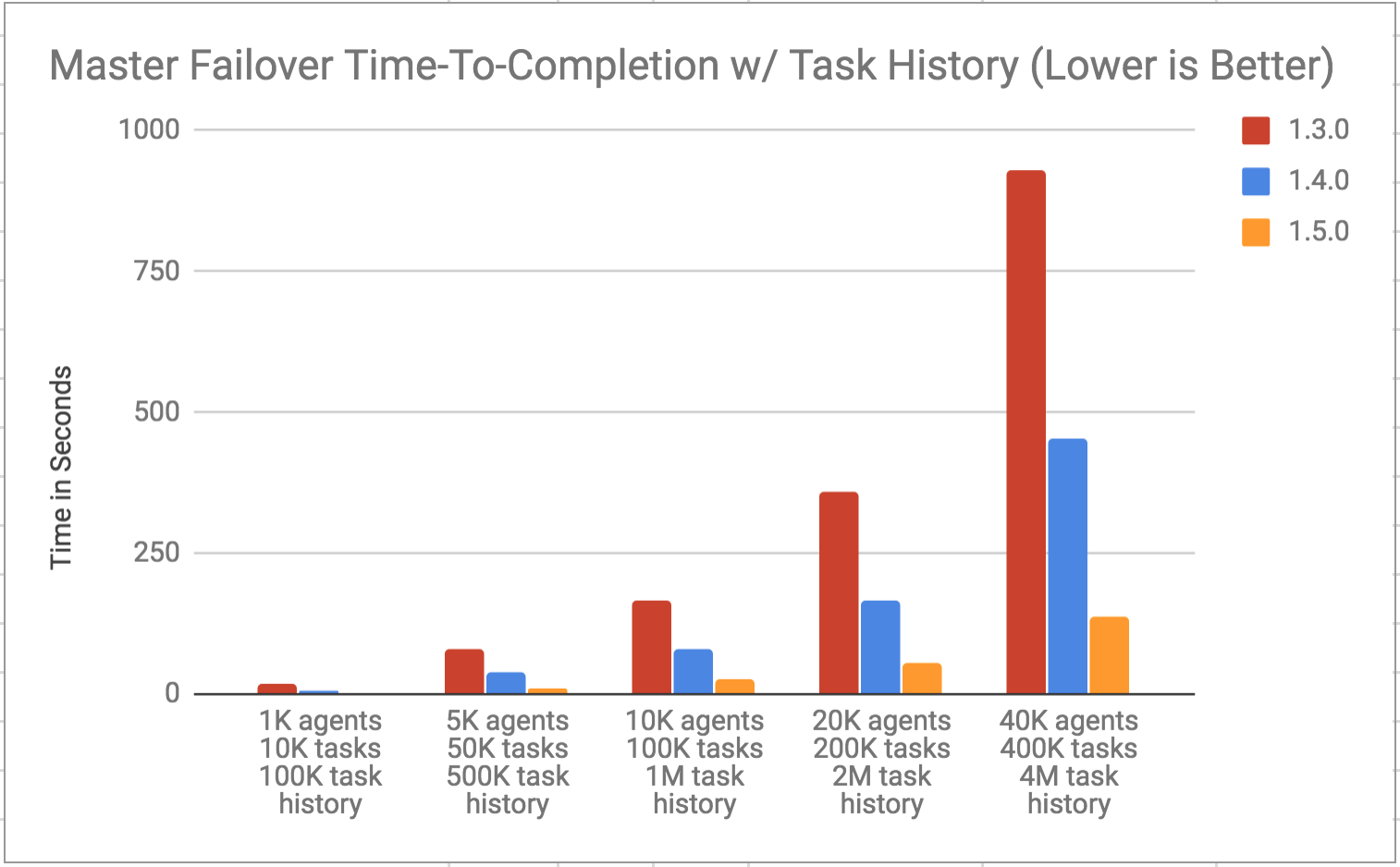
This represents a reduction in time-to-completion of ~85% due to a 550-700% improvement in throughput across 1.3.0 to 1.5.0.
Performance Working Group Roadmap
We’re currently targeting the following areas for improvements:
- Performance of the v1 API: Currently the v1 API can be significantly slower than the v0 API. We would like to reach parity, and ideally surpass the performance of the v0 API.
- Libprocess HTTP performance: This will be undertaken as part of improving the v1 API performance, since it is HTTP-based.
- Master state API performance: Currently, API queries of the master’s state are serviced by the same master actor that processes all of the messages from schedulers and agents. Since the query processing can block the master from processing other events, users need to be careful not to query the master excessively. In practice, the master gets queried quite heavily due to the presence of several tools that rely on the master’s state (e.g. DNS tooling, UIs, CLIs, etc) and so this is a critical problem for users. This effort will leverage the state streaming API to stream the state to a different actor that can serve the state API requests. This will ensure that expensive state queries do not affect the master’s ability to process events.
If you are a user and would like to suggest some areas for performance improvement, please let us know by emailing dev@apache.mesos.org.